VMware {code} : Sample Metadata Conventions
- Overview
- Sample Exchange Metadata
- Examples
Overview
When you select a given file as a sample, SX analyzes the file contents and attempts to figure out reasonable default metadata for the sample. The file name is used to create a name for the sample, it attempts to get the content of block comments at the beginning of the sample as a description, file extensions are used to figure out the programming language, etc. There are also a number of supported conventions that can be leveraged to explicitly specify these metadata values, making sample contribution frictionless for the contributor as well as enabling the possibility of completely automated contribution of samples. In effect, if metadata is explicitly provided in a sample that is added to a repository on Github that Sample Exchange has been configured to watch, then that sample can be automatically contributed.
This document outlines the flow that is used internally to derive sample metadata as well as detailing supported metadata conventions.
Sample Exchange Metadata
Metadata Sample Exchange needs
For each sample the following data is needed at contribution time. It is possible to specify
all of it with explicit metadata. Sample Exchanges also provides web services that attempt
to get defaults for all values using convention and heuristic analysis of the sample content.
The #Sample Metadata Analysis Flow
section contains detail of how values are defaulted.
- Name: Single line plain text title for the sample. Ideally any user should have a pretty good idea of what the sample is from this string alone. </span>
- Description: Multi-line HTML description of what the sample is for, what it does, and how to use it. Ideally this block of text tells the user what they need to know and no more. See "Description conventions" section below for other ways that this data can be maintained (such as in markdown files in the Github repo)</span>
- Platforms: Comma separated list of names of official VMware products and/or SDKs that this sample is related to. If this value is not explicitly provided, there are sets of keywords that the Sample Services look for to pick probable defaults. You can see a list at https://apigw.vmware.com/v1/m4/api/dcr/rest/apix/products.
- License: Sample Exchange only allows MIT, BSD, and Apache 2.0 licenses currently. You can explicitly provide which license is used, but there is also code that heuristically determines this by looking for "MIT", "BSD", or "Apache" in the first two block comments in any given source file.</span>
- Tags: Optional, but you can provide a comma separated list of tags/keywords that should be applied to your sample. May help improve discoverability. TODO link to service to see commonly used tags.
- Version: Optional, a version string for the sample if applicable.
- Language: Required, but in the majority of cases it can be determined reliably from the file extension of a given sample. In cases of Unix/shell scripts that omit file extension but embed the interpreter in the first comment (e.g. "#!/usr/bin/python" the code will look on the first line for "python", "ruby", or "perl"). In cases where it is ambiguous, e.g. a sample that is a zip of many files this may need to be explicitly selected.
Metadata required to enable automated sample contribution
Sample Services must be able to determine the following information from analysis of a given single sample file:
- Name: Must be explicitly provided in order to enable automated contribution.
- Description: Must be explicitly provided for automated contribution
- License: This field can be explicitly provided, though this should not be necessary. Every sample should have an explicit copyright statement as well as explicit unambiguous license terms. Sample exchange will look through the first two comment blocks in a file for "MIT", "BSD", or "Apache" (case doesn't matter) to determine the license. If these do not appear, the sample will not be automatically contributed.
- Language: In the automated contribution case, only known programming language file extensions are scanned to be contributed automatically, so there is no need to explicitly provide this. This is mentioned to highlight the fact that Unix shell conventions of embedding the interpreter in the first comment of the file for Python, Ruby, Perl and others will not work for automated contribution, the files must have a known extension.
Comment syntax
A note about comment blocks
"Comment block" in this documentation refers to either an explicit multi-line comment for languages that support them (e.g. Java, C#, C, C++, Python, Ruby, PowerShell), or a series of two or more adjacent lines that all start with a single line comment string. The Sample Exchange code that looks for metadata will look in the first two comment blocks only for metadata. The idea here is that it is common convention to have a leading comment block that contains a Copyright and license clause, and then in the next comment block (which may or may not follow import statements and such) provide sample metadata.
Block comments in Java, C#, C, C++, and Groovy
/*
This is a Java block comment (and C#, C, C++, Groovy)
*/
// Name: Sample of a Block Comment
// Description: This series of adjacent single line comments is also treated as
// a block that is analyzed to find metadata
// this line is not included because there is a non comment line in between however.
For Ruby and Python it is quite common to use blocks of single line comments. In this example, line 1, which is common shell script convention of specifying the interpreter, is ignored because it is a single line comment by itself. Lines 3-5 are the first "comment block". Lines 9-11 are the second comment block.
comment blocks in Python or Ruby
#!/usr/bin/python
# Copyright 2017 VMware Inc, All rights reserved. Released under the Apache 2.0 License
# This is the first "block comment"
# because it is two or more adjacent single line comments
from time import time
# Name: An example of this is the second block comment
# because there are two or more
# adjacent comment single line comments
"""
Sample Exchange stops parsing the sources looking for metadata after the second comment block at line
11, so this multi-line comment is actually ignored. (you have to stop somewhere...)
"""
class SomeSample(object):
...
Parse sequence notes
For each of the two leading comment blocks:
- Leading white space is stripped
- Leading single line comment strings are stripped (for single line comment blocks)
- Any leading '*' characters are stripped
- Regex used to match metadata field names, "^[a-zA-Z]+:". Case of the identifiers is ignored.
- One a field is discovered, the field is assumed to be ended by the next field (on a start of line), or the end of the comment block.
Description conventions
Of course no one wants dual maintenance with sample content. At the same
time it is nice to have a useful rich text description of the sample that can
have sections for topics such as setting up development environments,
authentication, and other topics. This creates a tension with where to maintain
the description of the sample, in the sample source file itself, or in some external README.md ?
What about cases where 10 samples share the same subset of instructions?
There is no one answer that can meet all requirements, and so there are a number of different ways that Sample Exchange supportsSample Exchange tries to create a simple and yet powerful set
Sample Metadata analysis flow
Items found later in the list override defaults earlier in the list. i.e. if you provide data explicitly it will override the defaults that were determined heuristically.
- Attempt to use the file name as the Name. Extension is dropped. Any underscores or dashes are turned into spaces. Camel case is split into spaces. First letters of any word are capitalized. Any VMware product names are then fixed (e.g. Vsphere -> vSphere), common acronyms are fixed to be all caps (e.g. VM, LDAP, RAM, SATA, ...). This produces fairly good results if the file name is delineated by dashs/underscores/camel case.
- Description defaults to the sample name (worst case. Hopefully overridden below)
- First two comment blocks are extracted from the file. If the first comment block contains "license" and "copyright", the second comment block is used as the default for Description, otherwise the first comment block is used as default for Description.
- Block that contains "license" (case independent)
- Both comment blocks are examined for explicit metadata tags. Any tags that are found for Name and Description override the defaults above. Comment blocks are also searched for keywords for defaults for Platforms and Tags. (e.g. vRO, vRA, ESXi, ...)
- If there is a file in the same directory with the same name but with a ".md" description, this is assumed to be a markdown format description for the sample and will override the Description. (it is also added as a part of the sample)
- Explicitly provided Description metadata may also contain a sequence of one or more Markdown file names separated by commas. The values may either be relative paths from the directory of the sample (e.g. mySample.md, path/to/mySample.md), or a full path from the repository root if starting with a leading slash, e.g. /docs/README.md. If there is no relative or absolute path info on the .md file, the current directory, and then parent directories are searched for the file. So, "README.md" will end up with the README.md in the repository root if there is no other. Multiple Markdown files are iterated and concatenated together to be the description of the sample.
Examples
Examples of samples that enable automated contribution
EXAMPLE 1: vSphere Automation Python sample
vCenter Automation vCenter VM Hardware Memory sample
#!/usr/bin/env python
"""
* *******************************************************
* Copyright (c) VMware, Inc. 2016. All Rights Reserved.
* SPDX-License-Identifier: MIT
* *******************************************************
*
* DISCLAIMER. THIS PROGRAM IS PROVIDED TO YOU "AS IS" WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, WHETHER ORAL OR WRITTEN,
* EXPRESS OR IMPLIED. THE AUTHOR SPECIFICALLY DISCLAIMS ANY IMPLIED
* WARRANTIES OR CONDITIONS OF MERCHANTABILITY, SATISFACTORY QUALITY,
* NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE.
"""
__author__ = 'VMware, Inc.'
__copyright__ = 'Copyright 2016 VMware, Inc. All rights reserved.'
__vcenter_version__ = '6.5+'
import atexit
from com.vmware.vcenter.vm.hardware_client import Memory
from samples.vsphere.common import vapiconnect
from samples.vsphere.common.sample_util import parse_cli_args_vm
from samples.vsphere.common.sample_util import pp
from samples.vsphere.vcenter.setup import testbed
from samples.vsphere.vcenter.helper.vm_helper import get_vm
"""
Name: vCenter VM Memory
Description: Demonstrates how to configure the memory related settings of a virtual machine.
Sample Prerequisites - The sample needs an existing VM.
"""
vm = None
vm_name = None
stub_config = None
...
This is an example of meeting the minimum requirements via a block comment with Name and Description fields and the header also containing a comment block that specifies the open source license:
In this case the first single line comment is ignored (since it is a single line by itself with no adjacent single line comments), and the first two block comments extracted.
The first block comment contains "license" and "copyright", so this block is scanned for supported license identifiers and "MIT" is found, this the license requirement is met. There are no matches to the metadata tag regex in the first block ("^[a-zA-Z]+:").
The second block is scanned for metadata tags and Name: and Description: are found. For all metadata values, from the next char after the : to the start of another metadata field or the end of the block comment is the value. "vCenter VM Memory" is taken as the name of the sample. For "Description:", there is no other known metadata field found (in this case because "Sample Prerequisities:" has whitespace in the middle of it, so the text to the end of the comment is taken as the description:
"Demonstrates how to configure the memory related settings of a virtual machine.
Sample Prerequisites - The sample needs an existing VM."
(Note that the original sample in Github as of 3/20/2017 has "Sample Prerequisities:\nThe sample needs an existing VM." This would actually work as well and be picked up as part of the description only because "Sample Prerequisities:" has whitespace in the name and thus does not match the regex used to find the start of metadata fields.
EXAMPLE 2: vSphere Automation Java Sample
This example is taken from vsphere-automation-sdk-java/src/main/java/vmware/samples/contentlibrary/crud/LibraryCrud.java . The sample has been modified to additionally include the sentence "
Java Example
/*
* *******************************************************
* Copyright VMware, Inc. 2016. All Rights Reserved.
* *******************************************************
*
* This software is open source provided under the terms
* of the MIT software license:
*
* DISCLAIMER. THIS PROGRAM IS PROVIDED TO YOU "AS IS" WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, WHETHER ORAL OR WRITTEN,
* EXPRESS OR IMPLIED. THE AUTHOR SPECIFICALLY DISCLAIMS ANY IMPLIED
* WARRANTIES OR CONDITIONS OF MERCHANTABILITY, SATISFACTORY QUALITY,
* NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE.
*/
package vmware.samples.contentlibrary.crud;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.UUID;
import org.apache.commons.cli.Option;
import com.vmware.content.LibraryModel;
import com.vmware.content.library.StorageBacking;
import com.vmware.vim25.ManagedObjectReference;
import vmware.samples.common.SamplesAbstractBase;
import vmware.samples.common.vim.helpers.VimUtil;
import vmware.samples.contentlibrary.client.ClsApiClient;
/**
* Name: Content Library CRUD
* Description: Demonstrates the basic operations of a content library. The sample also
* demonstrates the interoperability of the VIM and vAPI. Note: The sample needs
* an existing VC datastore with available storage.
*
*/
public class LibraryCrud extends SamplesAbstractBase {
...
Sample heuristic metadata discovery examples
These samples do not contain explicit metadata required for automated contribution, but are examples of Sample Exchange following its parsing rules to determine the default metadata for the sample that is shown to the user when contributing the sample in the Sample Exchange UI.
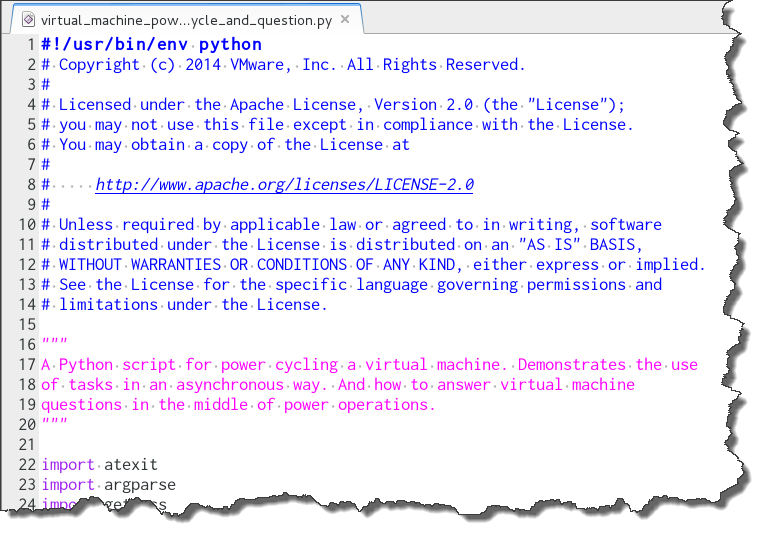
EXAMPLE 3: Pyvmomi virtual_machine_power_cycle_and_question.py sample
- Sample name is defaulted to "Virtual Machine Power Cycle And Question" from the file name
- Language is Python from the .py extension
- Body of file is analyzed and no explicit tags are found
- Initial comment block contains "Apache", so Apache 2.0 license is used.
- Initial comment block contains "Copyright" and "License", so it is assumed to be a copyright/license block and not a description of the sample.
- Second block comment is taken as the description ("A Python script for power cycling ...")
Beginning body of this file looks like:
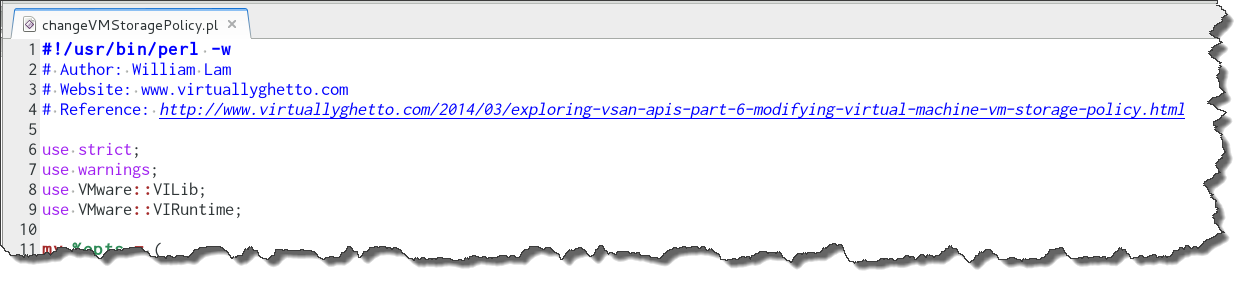
EXAMPLE 4: changeVMStoragePolicy.pl sample
https://github.com/lamw/vghetto-scripts/blob/master/perl/changeVMStoragePolicy.pl
- The name of the sample is defaulted from the file name "Change VM Storage Policy"
- Language is Perl from the .pl extension
- Initial line comments are analyzed for tags. "Author" and "Website" tags are ignored. From this we find a Reference tag. This page is resolved and the title used for a description, "Exploring VSAN APIs Part 6 – Modifying Virtual Machine VM Storage Policy"
The beginning body of the file looks like this:
Additional PowerShell conventions
PowerShell has its own pseudo-standard conventions for metadata embedded in leading comments. You can use the convention above or you can use the standard Microsoft convention (or both).
.LABEL Any following text is used as the name of the sample
.DESCRIPTION Any following multi-line text is used as the description of the sample.
.SYNOPSIS: Any following multi-line text is use as the description of the sample. (treated as an alias for .DESCRIPTION)
Case of the identifiers doesn't matter.
EXAMPLE 5 Execute_ESXCLI_PA.ps1 script from Alan Renouf's Github repository
https://github.com/alanrenouf/PowerActions/blob/master/Execute_ESXCLI_PA.ps1
- Name of sample is defaulted to "Execute ESXCLI PA" from the file name
- Description is defaulted to the sample name, "Execute ESXCLI PA"
- Language defaulted to PowerShell from .ps1 file extension
- Initial block comment is scanned and .LABEL overrides the name as "Execute ESXCLI commands"
- .DESCRIPTION in block comment overrides description to be "Allows execution of ESXCLI commands against an vSphere host through PowerActions."
